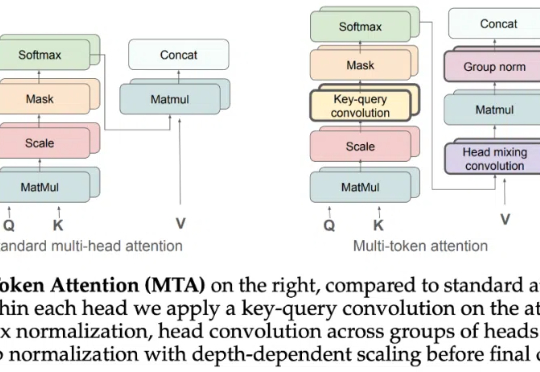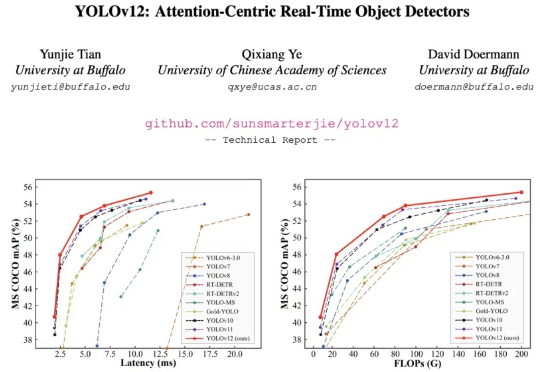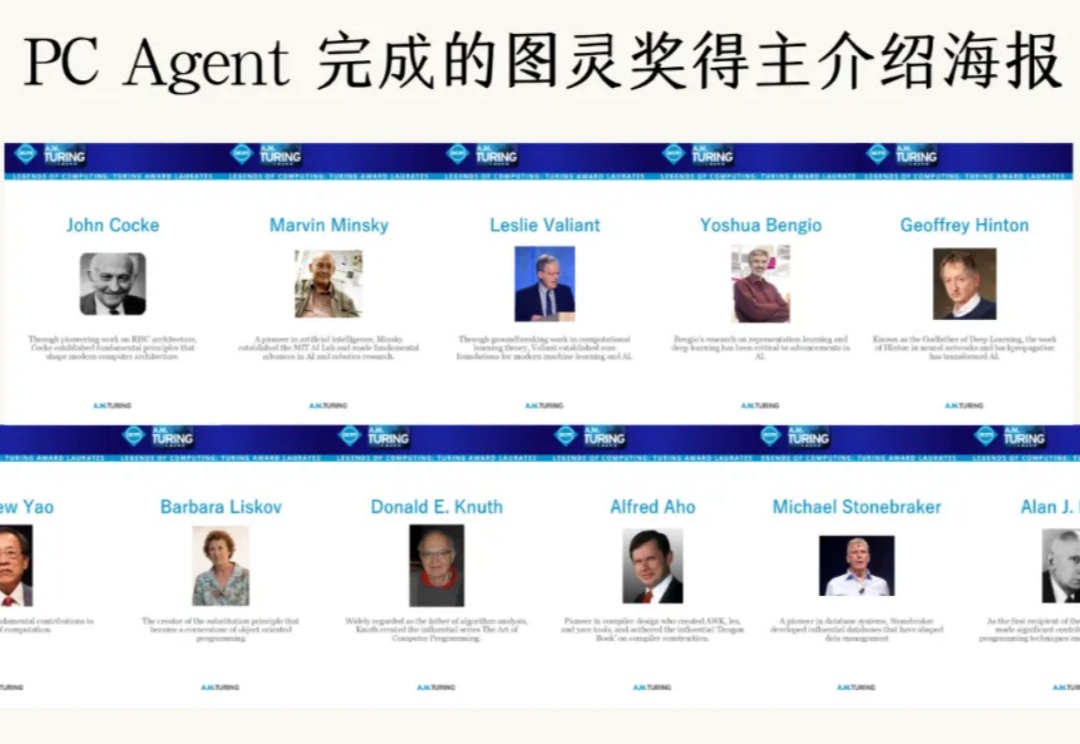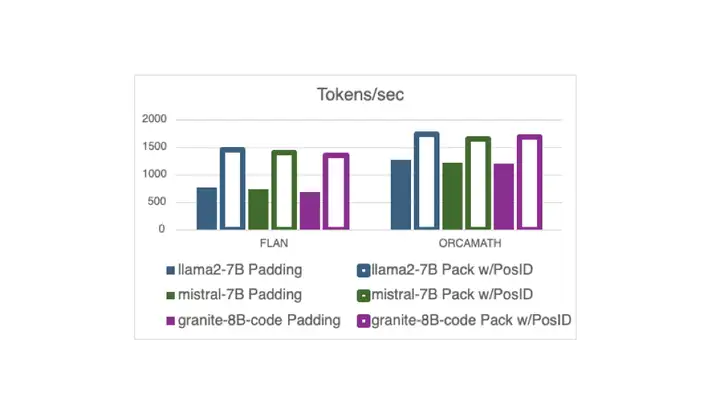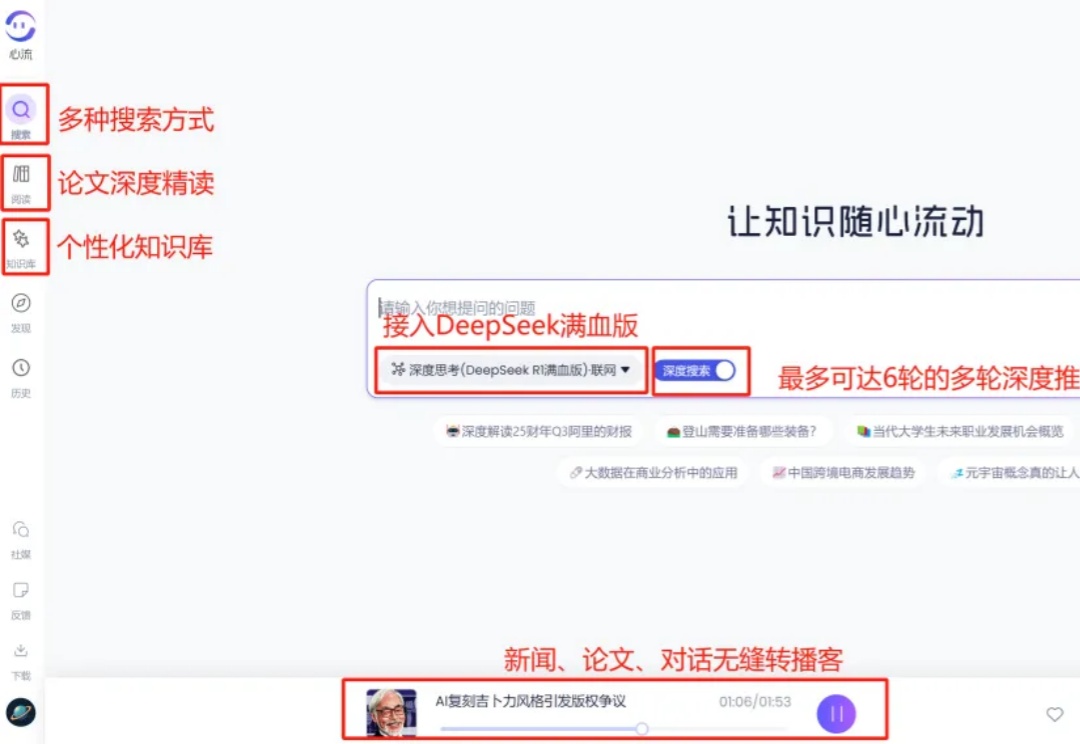
论文读得慢,可能是工具的锅,一手实测科研专用版「DeepSeek」
论文读得慢,可能是工具的锅,一手实测科研专用版「DeepSeek」「未来,99% 的 attention 将是大模型 attention,而不是人类 attention。」这是 AI 大牛 Andrej Karpathy 前段时间的一个预言。这里的「attention」可以理解为对内容的需求、处理和分析。也就是说,他预测未来绝大多数资料的处理工作将由大模型来完成,而不是人类。
来自主题: AI资讯
10396 点击 2025-04-07 17:09